
Hello! I am a first-year Computer Science student at the University of Illinois Urbana-Champaign, advised by Professor Dong Wang as a part of the Social Sensing & Intelligence (SSI) Lab. Previously, I completed my Master's and Bachelor's degrees in Computer Science at Johns Hopkins University, advised by Professor Kimia Ghobadi and Professor Tianmin Shu.
I am broadly interested in the research topics of human-centered AI and the intersections of AI and human cognition/reasoning .
Warning
Problem: The current name of your GitHub Pages repository ("Solution: Please consider renaming the repository to "
http://".
However, if the current repository name is intended, you can ignore this message by removing "{% include widgets/debug_repo_name.html %}" in index.html.
Action required
Problem: The current root path of this site is "baseurl ("_config.yml.
Solution: Please set the
baseurl in _config.yml to "Education
-
 University of Illinois Urbana-ChampaignDepartment of Computer Science
University of Illinois Urbana-ChampaignDepartment of Computer Science
Ph.D. StudentAug. 2025 - present -
 Johns Hopkins UniversityM.S.E in Computer ScienceJan. 2024 - Dec. 2024
Johns Hopkins UniversityM.S.E in Computer ScienceJan. 2024 - Dec. 2024 -
Johns Hopkins UniversityB.S. in Computer ScienceAug. 2020 - Dec. 2023
Honors & Awards
-
Amazon AI PhD Fellowship2025
News
Selected Publications (view all )
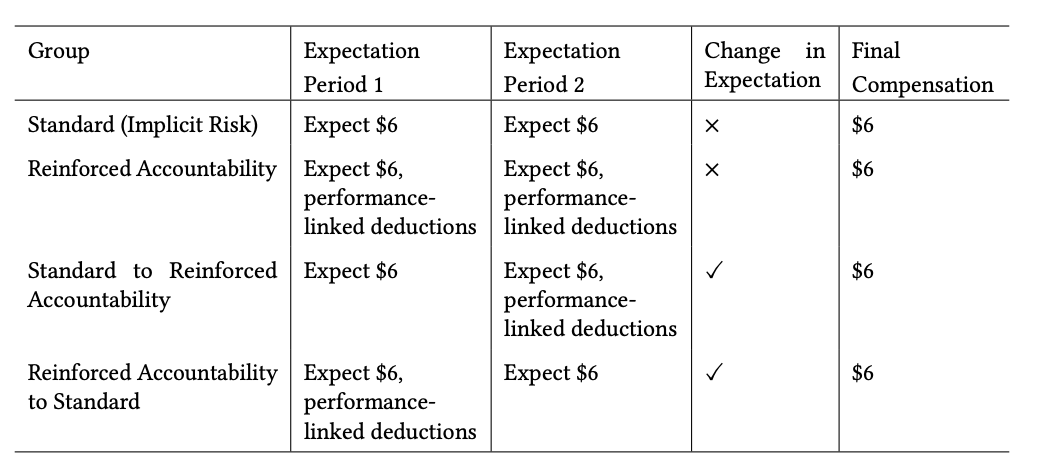
Dynamic Compensation Can Enhance User Engagement by Triggering Sensitivity to Financial Losses in Crowd-sourced Studies
Catalina Gomez*, Mung Yao Jia* , Sue Min Cho, Chien-Ming Huang, Mathias Unberath (* equal contribution)
Proceedings of the 2026 CHI Conference on Human Factors in Computing Systems 2026 Honourable Mention Award
Participation in crowd-sourced user studies is often driven by monetary incentives. However, standard payment schemes that reward completion unless responses are of poor quality may not invoke sufficient accountability. By compromising user engagement, a lack of accountability can affect data quality and the study’s ecological validity. Here, we investigate alternative compensation strategies that manipulate payment framing and evaluate their impact on engagement through task effort, outcomes, and perception. We compared a standard scheme with implicit rejection risk to a reinforced accountability condition with explicit performance-linked deductions, and two dynamic conditions that unexpectedly switched strategies. In a study with 106 Prolific participants on an image captioning task, we found that only shifting from implicit risk to reinforced accountability significantly increased engagement, likely due to loss aversion after participants had already invested time. The reverse shift decreased effort as observed in the standard group. Our results highlight the importance of carefully designing compensation schemes.
Dynamic Compensation Can Enhance User Engagement by Triggering Sensitivity to Financial Losses in Crowd-sourced Studies
Catalina Gomez*, Mung Yao Jia* , Sue Min Cho, Chien-Ming Huang, Mathias Unberath (* equal contribution)
Proceedings of the 2026 CHI Conference on Human Factors in Computing Systems 2026 Honourable Mention Award
Participation in crowd-sourced user studies is often driven by monetary incentives. However, standard payment schemes that reward completion unless responses are of poor quality may not invoke sufficient accountability. By compromising user engagement, a lack of accountability can affect data quality and the study’s ecological validity. Here, we investigate alternative compensation strategies that manipulate payment framing and evaluate their impact on engagement through task effort, outcomes, and perception. We compared a standard scheme with implicit rejection risk to a reinforced accountability condition with explicit performance-linked deductions, and two dynamic conditions that unexpectedly switched strategies. In a study with 106 Prolific participants on an image captioning task, we found that only shifting from implicit risk to reinforced accountability significantly increased engagement, likely due to loss aversion after participants had already invested time. The reverse shift decreased effort as observed in the standard group. Our results highlight the importance of carefully designing compensation schemes.
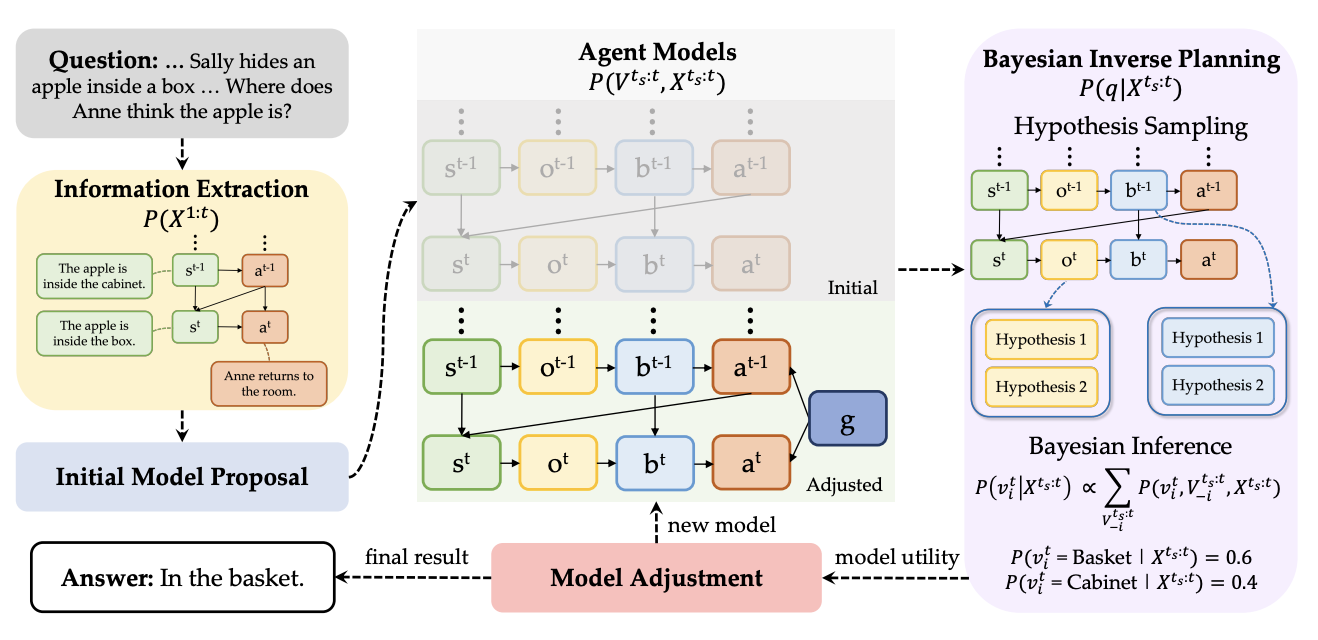
AutoToM: Scaling Model-based Mental Inference via Automated Agent Modeling
Zhining Zhang*, Chuanyang Jin*, Mung Yao Jia *, Shunchi Zhang*, Tianmin Shu (* equal contribution)
NeurIPS 2025 Spotlight
Theory of Mind (ToM), the ability to understand people’s minds based on their behavior, is key to developing socially intelligent agents. Current approaches to ToM reasoning either rely on prompting Large Language Models (LLMs), which are prone to systematic errors, or use handcrafted, rigid agent models for model-based inference, which are more robust but fail to generalize across domains. In this work, we introduce AutoToM, an automated agent modeling method for scalable, robust, and interpretable mental inference. Given a ToM problem, AutoToM first proposes an initial agent model and then performs automated Bayesian inverse planning based on this model, leveraging an LLM backend. Guided by inference uncertainty, it iteratively refines the model by introducing additional mental variables and/or incorporating more timesteps in the context. Across five diverse benchmarks, AutoToM outperforms existing ToM methods and even large reasoning models. Additionally, we show that AutoToM can produce human-like confidence estimates and enable online mental inference for embodied decision-making.
AutoToM: Scaling Model-based Mental Inference via Automated Agent Modeling
Zhining Zhang*, Chuanyang Jin*, Mung Yao Jia *, Shunchi Zhang*, Tianmin Shu (* equal contribution)
NeurIPS 2025 Spotlight
Theory of Mind (ToM), the ability to understand people’s minds based on their behavior, is key to developing socially intelligent agents. Current approaches to ToM reasoning either rely on prompting Large Language Models (LLMs), which are prone to systematic errors, or use handcrafted, rigid agent models for model-based inference, which are more robust but fail to generalize across domains. In this work, we introduce AutoToM, an automated agent modeling method for scalable, robust, and interpretable mental inference. Given a ToM problem, AutoToM first proposes an initial agent model and then performs automated Bayesian inverse planning based on this model, leveraging an LLM backend. Guided by inference uncertainty, it iteratively refines the model by introducing additional mental variables and/or incorporating more timesteps in the context. Across five diverse benchmarks, AutoToM outperforms existing ToM methods and even large reasoning models. Additionally, we show that AutoToM can produce human-like confidence estimates and enable online mental inference for embodied decision-making.
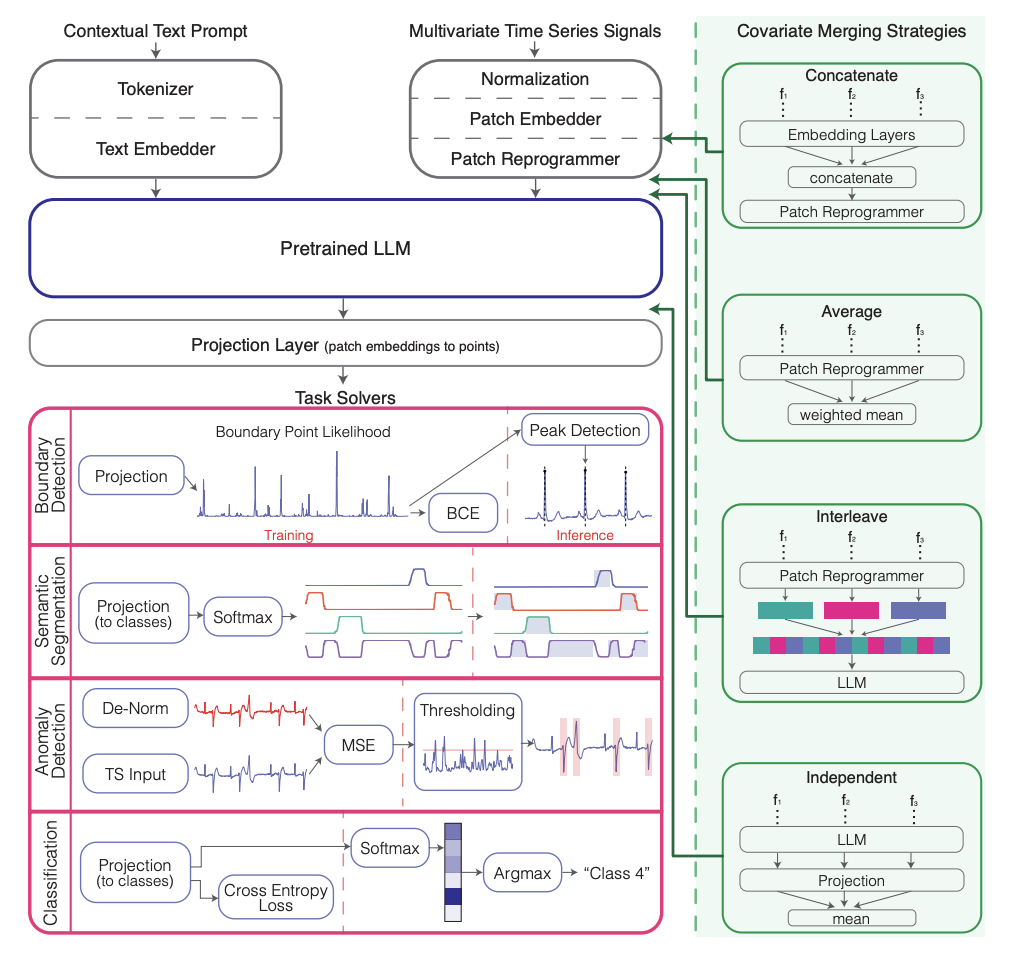
MedTsLLM: Leveraging LLMs for Multimodal Medical Time Series Analysis
Nimeesha Chan, Felix Parker, William Bennett, Tianyi Wu, Mung Yao Jia , James Fackler, Kimia Ghobadi
Machine Learning for Healthcare Conference. 2024
The complexity and heterogeneity of data in many real-world applications pose significant challenges for traditional machine learning and signal processing techniques. For instance, in medicine, effective analysis of diverse physiological signals is crucial for patient monitoring and clinical decision-making and yet highly challenging. We introduce MedTsLLM, a general multimodal large language model (LLM) framework that effectively integrates time series data and rich contextual information in the form of text to analyze physiological signals, performing three tasks with clinical relevance: semantic segmentation, boundary detection, and anomaly detection in time series. These critical tasks enable deeper analysis of physiological signals and can provide actionable insights for clinicians. We utilize a reprogramming layer to align embeddings of time series patches with a pretrained LLM's embedding space and make effective use of raw time series, in conjunction with textual context. Given the multivariate nature of medical datasets, we develop methods to handle multiple covariates. We additionally tailor the text prompt to include patient-specific information. Our model outperforms state-of-the-art baselines, including deep learning models, other LLMs, and clinical methods across multiple medical domains, specifically electrocardiograms and respiratory waveforms. MedTsLLM presents a promising step towards harnessing the power of LLMs for medical time series analysis that can elevate data-driven tools for clinicians and improve patient outcomes.
MedTsLLM: Leveraging LLMs for Multimodal Medical Time Series Analysis
Nimeesha Chan, Felix Parker, William Bennett, Tianyi Wu, Mung Yao Jia , James Fackler, Kimia Ghobadi
Machine Learning for Healthcare Conference. 2024
The complexity and heterogeneity of data in many real-world applications pose significant challenges for traditional machine learning and signal processing techniques. For instance, in medicine, effective analysis of diverse physiological signals is crucial for patient monitoring and clinical decision-making and yet highly challenging. We introduce MedTsLLM, a general multimodal large language model (LLM) framework that effectively integrates time series data and rich contextual information in the form of text to analyze physiological signals, performing three tasks with clinical relevance: semantic segmentation, boundary detection, and anomaly detection in time series. These critical tasks enable deeper analysis of physiological signals and can provide actionable insights for clinicians. We utilize a reprogramming layer to align embeddings of time series patches with a pretrained LLM's embedding space and make effective use of raw time series, in conjunction with textual context. Given the multivariate nature of medical datasets, we develop methods to handle multiple covariates. We additionally tailor the text prompt to include patient-specific information. Our model outperforms state-of-the-art baselines, including deep learning models, other LLMs, and clinical methods across multiple medical domains, specifically electrocardiograms and respiratory waveforms. MedTsLLM presents a promising step towards harnessing the power of LLMs for medical time series analysis that can elevate data-driven tools for clinicians and improve patient outcomes.